
소개
- 회사 - 제로엑스플로우
- 기간 - 23.07.12 ~ 24.02.21
- 프로젝트 명 - ChatGPT 배치 서비스
- 목적 - AI 활용 기능 도입 및 확장
- 참여인력 - 백엔드 · 인프라 개발 1, 프론트엔드 개발 1 (웹 소캣 연결 및 재 연결 처리)
- 기술스택
- 배치 서비스 - Python, AWS SQS, AWS Lambda, API Gateway(웹소켓), DynamoDB
- 원아워 서비스 - Python, Django, PostgreSQL, DynamoDB, AWS Lambda, Zappa
- 담당 - 백엔드 · 인프라 개발
도입
교육 서비스 '원아워' 의 기존의 AI 활용 기능의 제약을 해결하기 위해 시작하게 된 프로젝트이자, AI 코스웨어로의 첫 걸음을 내딛을 수 있게 해준 프로젝트이다. 기존의 AI 기능들은 원아워 서버를 통해서 제공하고 있었고 API Gateway 의 타임아웃의 최대 시간이 30초였기에, LLM 의 응답시간에 맞게 30초에 맞춰 ChatGPT 프롬프트를 소극적으로 활용할 수밖에 없었다. 해당 프로젝트는 런칭 이후에 총 3번의 큰 변화를 겪었다. 이번 글에서는 그 과정에서 필자의 경험과 생각을 적어보려고 한다.
요약
| 내용 | 기간 | |
| 1차 | AWS SQS 을 이용한 ChatGPT 요청 원아워 서버에서 분리 | 23.07.12 ~ 23.07.25 |
| 2차 | ChatGPT Prompt DynamoDB 로 이관 ( with 프롬프트 백오피스 CLI ) | 23.08.01 ~ 23.08.02 |
| 3차 | ChatGPT 요청 전 후 작업이 가능하도록 리팩토링 ( for AI 영작 ) | 23.08.18 ~ 23.08.22 ( 유지보수 : ~ 23.12.23 ) |
| 4차 | 원아워 비즈니스 로직과 메세지 큐에 대한 분리 작업 | 24.01.14 ~ 24.01.15 ( 유지보수 : ~ 24.02.19 ) |
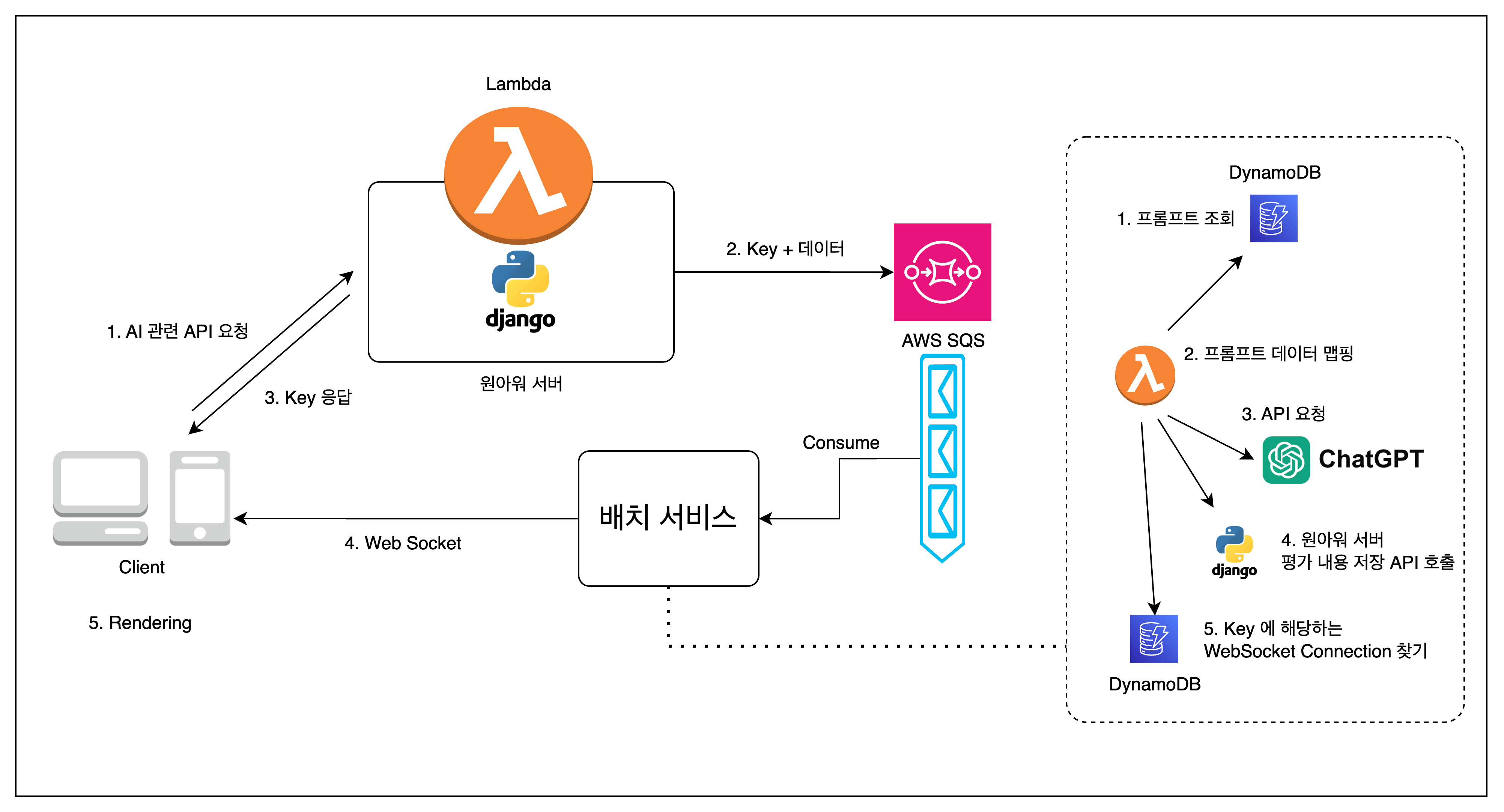
#1 AWS SQS 을 이용한 ChatGPT 요청 원아워 서버에서 분리 (2023, 07.12 ~ 07.25)
위에서 언급했듯이 원아워 서버에 프롬프트 관련 정보가 소스코드에 포함이 되어 있었기에 2가지 문제점이 존재했다. 첫 번째는 ChatGPT 요청 시간으로 인해 람다가 점유되는 문제가 존재했으며, 람다의 타임아웃은 최대 15분까지 설정할 수 있었으나, API Gateway 의 timeout 은 29초가 최대였다. 이로 인해, ChatGPT 의 강력한 기능들을 활용하지 못했다.
ChatGPT 를 통해 특정 지문에 대해서 특정 유형의 영어 문제를 제작한다고 했을 때, 한번에 만들 수 있는 문제의 수가 5문제, 또 지문의 길이 제한도 있었다.
이러한 문제점들을 해결하기 위해 원아워 API 서버와 ChatGPT 요청 작업을 분리하여 배치 서버를 구축하고자 메세지 큐인 AWS SQS 를 사용했다. 많은 메세지 큐 중 AWS SQS 를 선택한 이유는 AWS 서버리스 인프라를 적극 활용하고 있는 상태에서 비용, 작업 난이도 등을 고려했을 때, 빠르게 적용할 수 있을 거라판단했다.
ChatGPT 같은 경우 프롬프트 주제와 요청한 응답데이터의 크기에 따라 시간의 편차가 큰 편이다. 그렇기에 AWS SQS 에서 ChatGPT 로 요청을 보내고 응답을 받은 후, 해당 메세지 큐에 티켓을 발행한 유저의 웹소켓으로 결과를 보내주는 방식으로 설계했다.
성과
1. ChatGPT 의 성능을 적극적으로 활용할 수 있게 되었다. ( 기능 수 4개 👉🏻 32개 )
2. 원아워 API 서버의 트래픽 부하를 분산했다. ( 람다 점유 방지 )
#2 DynamoDB 로 프롬프트 이관 with 프롬프트 편집 작업을 할 수 있는 CLI 제작 (2023, 08.01 ~ 08.02)
프롬프트가 원아워 서버에서 분리가 된 것은 맞지만, AWS SQS 를 활용한 배치서버의 소스코드에 프롬프트가 여전히 포함되어 있었다. 따라서, 프롬프트의 추가, 수정, 삭제를 하기 위해서는 AWS SQS 와 AWS Lambda 를 다시 배포해야만 했다. 물론, 테라폼을 이용하고 있었기에, 배포는 빠르게 적용할 수 있었으나, 프롬프트의 추가, 테스트, 간단한 수정 등에 개발자의 리소스가 소모가 되었다.
영우님, 프롬프트 이렇게 수정해 주세요. 영우님, 이거 테스트해보고 싶어요. 영우님 ~~~
이 문제를 해결하기 위해 ChatGPT 프롬프트를 DynamoDB 로 이관하는 작업을 했다. DynamoDB 의 AWS 콘솔창에 가서 직접 추가 및 수정을 할 수 있었지만 이렇게 된다면, 원아워 서비스가 의존하는 AI 기능에 대한 변경사항을 추적할 수가 없었다. 따라서 새로운 프롬프트를 추가하는 경우에만 AWS 콘솔에서 추가하고, 모든 프롬프트는 배포 버젼과 히스토리가 버져닝이 될 수 있도록 CLI 프로그램을 설계했다. 어찌 보면 비개발자(기획자)가 서비스 운영에 직접적인 영향을 줄 수 있기에, 그 과정에서 발생할 수 있는 최대한의 문제를 사전에 예방해야만 했다.
성과
AI 관련 기획에 있어 개발자의 리소스를 최소화 했으며, 기획자 또한 기획과 테스트에 있어 개발자의 리소스 할당이라는 병목구간을 제거했다.
#3 ChatGPT 요청 전 후 커스텀 동작 추가할 수 있도록 리팩토링 (2023, 08.18 ~ 08.22)
기존 과제 플로우
1. 기존의 과제들은 과제별로 성적을 확인할 수 있음
2. 해당 과제를 부여받은 학생들의 성적 확인 가능
3. 특정 학생의 특정 과제에 대한 분석리포트를 확인할 수 있음
4. 특정 학생에 대한 월별 과제 수행 내역도 확인할 수 있음
5. 과제 채점에 대해서는 기존 과제들은 이미 정답이 있어, 정답을 채점하고 해당 결과를 바로 저장할 수 있음
새롭게 기획중 인 AI 영작 기능은 기존의 과제와 저장 매커니즘이 달랐다. 과제에 대한 학생의 대답이 저장된 이후 ChatGPT 의 결과와 나왔을 때, 업데이트 되는 방식이다. (결과는 저장되었는데, 점수가 없는 상태가 발생) 따라서 기존의 ChatGPT 를 활용한 다른 기능들과 다르게 요청 결과를 웹소캣을 통해 전송하는 것 말고도 그 결과를 DB에 반영해야만 했다.
- ChatGPT 결과를 받아서, 클라이언트에서 그 결과를 저장하는 API 를 호출한다.
- ChatGPT 결과가 나왔을 때, 해당 결과를 반영하고 웹소캣으로 결과를 전송한다.
분명 첫 번째 방법이 구현에 드는 시간은 보다 빨랐지만, 웹소캣에 전송했을 때, 사용자의 네트워크에 따라 결과를 받지 못하는 경우도 발생할 수 있다고 생각이 들었기에 두 번째 방법을 선택했다. 구현 방법은 Python Django 의 미들웨어의 동작을 모방하여 전 · 후 처리를 손쉽게 적용할 수 있도록 설계했다.
AI 영작의 데이터 클래스를 원아워, 배치 서버 두 곳에 정의하여 DynamoDB 에 저장하고 해당 결과를 원아워 서비스에서 활용할 수 있게 설계를 했다. 처음 데이터 모델은 복잡하지 않았으며, AI 영작 결과를 활용한 기능이 단건 조회말고는 없었기에 두 곳에 정의하는 것이 큰 문제가 되지 않았다.
# b.py
import importlib
# 공통 함수 실행기: 함수가 없으면 기본 함수를 실행
def run_function(module_name, function_name, default_func, **kwargs):
try:
# 동적으로 모듈 불러오기
module = importlib.import_module(module_name)
# 함수 이름으로 함수 객체 찾기
func = getattr(module, function_name, None)
# callable이면 호출, 그렇지 않으면 기본 함수 호출
if callable(func):
return func(**kwargs)
else:
return default_func(**kwargs)
except ImportError as e:
print(f"Error importing module '{module_name}': {e}")
return default_func(**kwargs)
# task_name에 따라 적절한 함수 호출
def execute_task(task_name, req, prompt):
module_name = 'a'
# 함수명 조합
pre_function_name = f"process_request_for_TASK_{task_name}"
post_function_name = f"process_response_for_TASK_{task_name}"
# 전처리 단계
req = run_function(module_name, pre_function_name, process_request, req=req)
# AI 응답 요청
res = get_chatgpt_response(prompt, req)
# 후처리 단계
req, res = run_function(module_name, post_function_name, process_response, req=req, res=res)
return req, res
def get_prompt(task_name):
# TODO: Get Prompt by task_name from DynamoDB
return "~~~~"
task_name = "WRITING_AI"
req = {"key": "value"} # 예시 요청 데이터
prompt = get_prompt(task_name) # "~~~~"
# 함수 실행
req, res = execute_task(task_name, req, prompt)# a.py
# Default request handler
def process_request(req):
return req
# Default response handler
def process_response(req, res):
return req, res
# task 별로 필요한 경우 아래 이름 규칙에 맞게 정의하면 된다.
def process_request_for_TASK_WRITING_AI(req):
# TODO: Implement task 'WRITING_AI' request processing
result = WritingAIResult(**req['data'])
result.save()
return res
def process_response_for_TASK_WRITING_AI(req, res):
# TODO: Implement task 'WRITING_AI' response processing
result = WritingAIResult.find(**req['data'])
result.update(res)
result.save()
return req, res성과
프롬프트별로 요청 전 후로 필요한 작업들을 정해진 함수 이름규칙으로 선언 및 정의를 하게 되면 커스텀 동작을 쉽게 추가할 수 있게 되었다
다양한 프롬프트가 존재하며, 프롬프트의 내용은 DynamoDB 로 분리되어 있고, 전 후 처리에 대한 코드도 별도의 함수로 각각 존재하므로, 유지보수가 쉬워졌다.
문제점
하지만, 이러한 구조를 선택했기에 몇개월간의 추가 작업이 진행되면서 몇 가지 문제점을 확인할 수 있었다.
- 데이터 모델의 복잡도는 올라감에 따라, 원아워 서버와 람다에 데이터 모델이 중복해서 정의가 되어 있었기에 맞추는 과정에서 어려움이 많았다. (배포 순서, 오타 및 누락)
- AWS SQS 에서 PostgreSQL 에 접근해야 하는 상황이 발생했다. 원아워 API 서버가 불안정한 상태였기에, 트래픽이 몰리는 상황과, PostgreSQL 의 커넥션이 급증하는 상황을 막아야만 했다. 따라서, RDB 에 대한 접근을 허용할 수 없었다.
#4 비즈니스 로직 분리 (2024, 01.14 ~ 01.15)
3번째 프로젝트에서 발생한 문제들을 해결하기 위해 AWS SQS 에서는 원아워 서버의 API 를 호출하는 방식으로 변경했다. 즉, 원아워의 모든 비즈니스 로직은 원아워 API 서버를 통해 관리하며, AWS SQS 는 조금 더 단일 목적 ( ChatGPT 대리 요청 및 전 후처리에 대한 정의 ) 에 집중하게 했다.
개발을 하면서 오토마타 수업때 배웠던 것들이 떠올랐다. 느낌이 비슷했다.
1. 사용자가 AI 기능 요청
2. AI 기능 요청 전에 처리해야할 로직 수행
3. 티켓 발행
4. 티켓 처리 : ChatGPT 에게 요청
5. ChatGPT 응답 수신 후 정의되어 있는 후처리 API 호출
6. 클라이언트에 웹소캣을 통해 결과 전송
# a.py
import requests
def process_response_for_TASK_WRITING_AI(req, res):
payload = ...
url = f"{ONEHOUR_API_SERVER}/~~~"
requests.put(url, res)
return req, res성과
특별한 일이 있지 않는 한, SQS 소스코드를 수정할 필요가 없어졌다. 역할 분리를 통한 유지보수성이 좋아졌다.
마무리
리팩토링한 변화과정을 간단하게 그림으로 보면 다음과 같다.
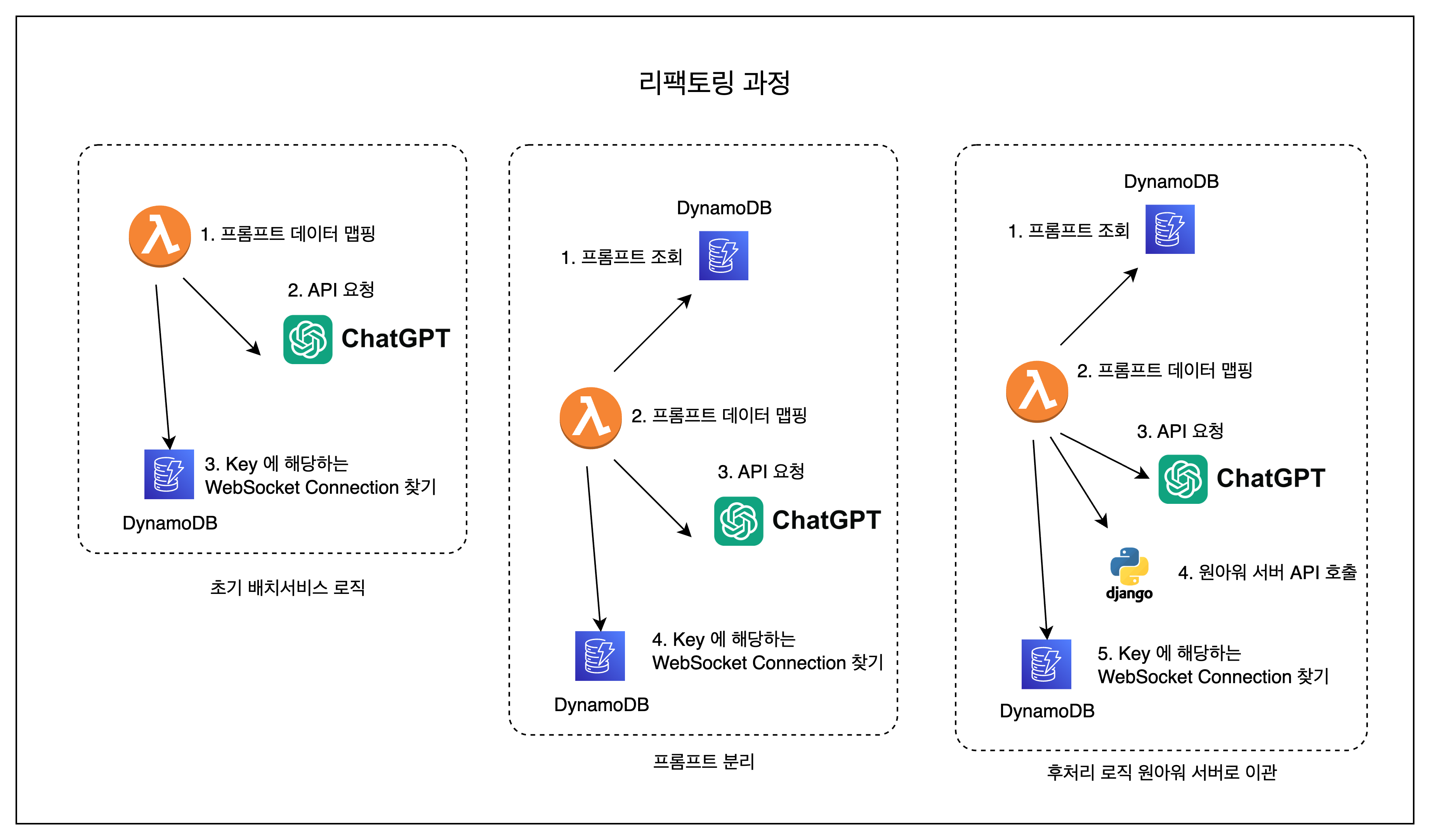
느낀 점
- 좋은 코드가 결국에는 시간을 단축시켜준다.
- 한번에 완벽하게 만들어낼 수 없다. ( 나중에 경험이 아주아주아주아주 많이 쌓인다고 하더라도, 몇 번의 트러블 슈팅과 리팩토링은 필요할거(같)다??!! )
- AWS 인프라에 대한 다양한 트러블 슈팅 경험을 얻을 수 있었다.
- AI 기능이 시장에서 아주 큰 영향을 미친다는 것을 알 수 있었다.
- 서울시 교육청과의 계약
- 스콜라스틱, 디즈니와 같은 큰 교육 미디어 회사와의 계약
- 시리즈 A 투자 유치에 큰 기여
- 팀원의 역량을 발휘할 수 있게 도와주는 백오피스 시스템의 중요성을 알게 되었다.
아쉬운 점
- AI 의 핵심 기능이라고 생각하는 스트리밍에 대한 처리는 적용해보지 못했다.
- 스타트업 특성상 새로운 기능을 개발하고 유지보수하는 것이 조금 더 강조되었기에 기술적으로 깊게 학습하기에는 어려움이 있었다.
- 다른 기업들에게 서비스를 제공하는 OPEN API 를 만들지 못했다.
'포트폴리오 > 경력' 카테고리의 다른 글
| 원아워 서비스 장악하기 - 중앙 집중식 로깅 시스템 구축 (0) | 2024.09.20 |
|---|
소개
- 회사 - 제로엑스플로우
- 기간 - 23.07.12 ~ 24.02.21
- 프로젝트 명 - ChatGPT 배치 서비스
- 목적 - AI 활용 기능 도입 및 확장
- 참여인력 - 백엔드 · 인프라 개발 1, 프론트엔드 개발 1 (웹 소캣 연결 및 재 연결 처리)
- 기술스택
- 배치 서비스 - Python, AWS SQS, AWS Lambda, API Gateway(웹소켓), DynamoDB
- 원아워 서비스 - Python, Django, PostgreSQL, DynamoDB, AWS Lambda, Zappa
- 담당 - 백엔드 · 인프라 개발
도입
교육 서비스 '원아워' 의 기존의 AI 활용 기능의 제약을 해결하기 위해 시작하게 된 프로젝트이자, AI 코스웨어로의 첫 걸음을 내딛을 수 있게 해준 프로젝트이다. 기존의 AI 기능들은 원아워 서버를 통해서 제공하고 있었고 API Gateway 의 타임아웃의 최대 시간이 30초였기에, LLM 의 응답시간에 맞게 30초에 맞춰 ChatGPT 프롬프트를 소극적으로 활용할 수밖에 없었다. 해당 프로젝트는 런칭 이후에 총 3번의 큰 변화를 겪었다. 이번 글에서는 그 과정에서 필자의 경험과 생각을 적어보려고 한다.
요약
| 내용 | 기간 | |
| 1차 | AWS SQS 을 이용한 ChatGPT 요청 원아워 서버에서 분리 | 23.07.12 ~ 23.07.25 |
| 2차 | ChatGPT Prompt DynamoDB 로 이관 ( with 프롬프트 백오피스 CLI ) | 23.08.01 ~ 23.08.02 |
| 3차 | ChatGPT 요청 전 후 작업이 가능하도록 리팩토링 ( for AI 영작 ) | 23.08.18 ~ 23.08.22 ( 유지보수 : ~ 23.12.23 ) |
| 4차 | 원아워 비즈니스 로직과 메세지 큐에 대한 분리 작업 | 24.01.14 ~ 24.01.15 ( 유지보수 : ~ 24.02.19 ) |
#1 AWS SQS 을 이용한 ChatGPT 요청 원아워 서버에서 분리 (2023, 07.12 ~ 07.25)
위에서 언급했듯이 원아워 서버에 프롬프트 관련 정보가 소스코드에 포함이 되어 있었기에 2가지 문제점이 존재했다. 첫 번째는 ChatGPT 요청 시간으로 인해 람다가 점유되는 문제가 존재했으며, 람다의 타임아웃은 최대 15분까지 설정할 수 있었으나, API Gateway 의 timeout 은 29초가 최대였다. 이로 인해, ChatGPT 의 강력한 기능들을 활용하지 못했다.
ChatGPT 를 통해 특정 지문에 대해서 특정 유형의 영어 문제를 제작한다고 했을 때, 한번에 만들 수 있는 문제의 수가 5문제, 또 지문의 길이 제한도 있었다.
이러한 문제점들을 해결하기 위해 원아워 API 서버와 ChatGPT 요청 작업을 분리하여 배치 서버를 구축하고자 메세지 큐인 AWS SQS 를 사용했다. 많은 메세지 큐 중 AWS SQS 를 선택한 이유는 AWS 서버리스 인프라를 적극 활용하고 있는 상태에서 비용, 작업 난이도 등을 고려했을 때, 빠르게 적용할 수 있을 거라판단했다.
ChatGPT 같은 경우 프롬프트 주제와 요청한 응답데이터의 크기에 따라 시간의 편차가 큰 편이다. 그렇기에 AWS SQS 에서 ChatGPT 로 요청을 보내고 응답을 받은 후, 해당 메세지 큐에 티켓을 발행한 유저의 웹소켓으로 결과를 보내주는 방식으로 설계했다.
성과
1. ChatGPT 의 성능을 적극적으로 활용할 수 있게 되었다. ( 기능 수 4개 👉🏻 32개 )
2. 원아워 API 서버의 트래픽 부하를 분산했다. ( 람다 점유 방지 )
#2 DynamoDB 로 프롬프트 이관 with 프롬프트 편집 작업을 할 수 있는 CLI 제작 (2023, 08.01 ~ 08.02)
프롬프트가 원아워 서버에서 분리가 된 것은 맞지만, AWS SQS 를 활용한 배치서버의 소스코드에 프롬프트가 여전히 포함되어 있었다. 따라서, 프롬프트의 추가, 수정, 삭제를 하기 위해서는 AWS SQS 와 AWS Lambda 를 다시 배포해야만 했다. 물론, 테라폼을 이용하고 있었기에, 배포는 빠르게 적용할 수 있었으나, 프롬프트의 추가, 테스트, 간단한 수정 등에 개발자의 리소스가 소모가 되었다.
영우님, 프롬프트 이렇게 수정해 주세요. 영우님, 이거 테스트해보고 싶어요. 영우님 ~~~
이 문제를 해결하기 위해 ChatGPT 프롬프트를 DynamoDB 로 이관하는 작업을 했다. DynamoDB 의 AWS 콘솔창에 가서 직접 추가 및 수정을 할 수 있었지만 이렇게 된다면, 원아워 서비스가 의존하는 AI 기능에 대한 변경사항을 추적할 수가 없었다. 따라서 새로운 프롬프트를 추가하는 경우에만 AWS 콘솔에서 추가하고, 모든 프롬프트는 배포 버젼과 히스토리가 버져닝이 될 수 있도록 CLI 프로그램을 설계했다. 어찌 보면 비개발자(기획자)가 서비스 운영에 직접적인 영향을 줄 수 있기에, 그 과정에서 발생할 수 있는 최대한의 문제를 사전에 예방해야만 했다.
성과
AI 관련 기획에 있어 개발자의 리소스를 최소화 했으며, 기획자 또한 기획과 테스트에 있어 개발자의 리소스 할당이라는 병목구간을 제거했다.
#3 ChatGPT 요청 전 후 커스텀 동작 추가할 수 있도록 리팩토링 (2023, 08.18 ~ 08.22)
기존 과제 플로우
1. 기존의 과제들은 과제별로 성적을 확인할 수 있음
2. 해당 과제를 부여받은 학생들의 성적 확인 가능
3. 특정 학생의 특정 과제에 대한 분석리포트를 확인할 수 있음
4. 특정 학생에 대한 월별 과제 수행 내역도 확인할 수 있음
5. 과제 채점에 대해서는 기존 과제들은 이미 정답이 있어, 정답을 채점하고 해당 결과를 바로 저장할 수 있음
새롭게 기획중 인 AI 영작 기능은 기존의 과제와 저장 매커니즘이 달랐다. 과제에 대한 학생의 대답이 저장된 이후 ChatGPT 의 결과와 나왔을 때, 업데이트 되는 방식이다. (결과는 저장되었는데, 점수가 없는 상태가 발생) 따라서 기존의 ChatGPT 를 활용한 다른 기능들과 다르게 요청 결과를 웹소캣을 통해 전송하는 것 말고도 그 결과를 DB에 반영해야만 했다.
- ChatGPT 결과를 받아서, 클라이언트에서 그 결과를 저장하는 API 를 호출한다.
- ChatGPT 결과가 나왔을 때, 해당 결과를 반영하고 웹소캣으로 결과를 전송한다.
분명 첫 번째 방법이 구현에 드는 시간은 보다 빨랐지만, 웹소캣에 전송했을 때, 사용자의 네트워크에 따라 결과를 받지 못하는 경우도 발생할 수 있다고 생각이 들었기에 두 번째 방법을 선택했다. 구현 방법은 Python Django 의 미들웨어의 동작을 모방하여 전 · 후 처리를 손쉽게 적용할 수 있도록 설계했다.
AI 영작의 데이터 클래스를 원아워, 배치 서버 두 곳에 정의하여 DynamoDB 에 저장하고 해당 결과를 원아워 서비스에서 활용할 수 있게 설계를 했다. 처음 데이터 모델은 복잡하지 않았으며, AI 영작 결과를 활용한 기능이 단건 조회말고는 없었기에 두 곳에 정의하는 것이 큰 문제가 되지 않았다.
# b.py
import importlib
# 공통 함수 실행기: 함수가 없으면 기본 함수를 실행
def run_function(module_name, function_name, default_func, **kwargs):
try:
# 동적으로 모듈 불러오기
module = importlib.import_module(module_name)
# 함수 이름으로 함수 객체 찾기
func = getattr(module, function_name, None)
# callable이면 호출, 그렇지 않으면 기본 함수 호출
if callable(func):
return func(**kwargs)
else:
return default_func(**kwargs)
except ImportError as e:
print(f"Error importing module '{module_name}': {e}")
return default_func(**kwargs)
# task_name에 따라 적절한 함수 호출
def execute_task(task_name, req, prompt):
module_name = 'a'
# 함수명 조합
pre_function_name = f"process_request_for_TASK_{task_name}"
post_function_name = f"process_response_for_TASK_{task_name}"
# 전처리 단계
req = run_function(module_name, pre_function_name, process_request, req=req)
# AI 응답 요청
res = get_chatgpt_response(prompt, req)
# 후처리 단계
req, res = run_function(module_name, post_function_name, process_response, req=req, res=res)
return req, res
def get_prompt(task_name):
# TODO: Get Prompt by task_name from DynamoDB
return "~~~~"
task_name = "WRITING_AI"
req = {"key": "value"} # 예시 요청 데이터
prompt = get_prompt(task_name) # "~~~~"
# 함수 실행
req, res = execute_task(task_name, req, prompt)# a.py
# Default request handler
def process_request(req):
return req
# Default response handler
def process_response(req, res):
return req, res
# task 별로 필요한 경우 아래 이름 규칙에 맞게 정의하면 된다.
def process_request_for_TASK_WRITING_AI(req):
# TODO: Implement task 'WRITING_AI' request processing
result = WritingAIResult(**req['data'])
result.save()
return res
def process_response_for_TASK_WRITING_AI(req, res):
# TODO: Implement task 'WRITING_AI' response processing
result = WritingAIResult.find(**req['data'])
result.update(res)
result.save()
return req, res성과
프롬프트별로 요청 전 후로 필요한 작업들을 정해진 함수 이름규칙으로 선언 및 정의를 하게 되면 커스텀 동작을 쉽게 추가할 수 있게 되었다
다양한 프롬프트가 존재하며, 프롬프트의 내용은 DynamoDB 로 분리되어 있고, 전 후 처리에 대한 코드도 별도의 함수로 각각 존재하므로, 유지보수가 쉬워졌다.
문제점
하지만, 이러한 구조를 선택했기에 몇개월간의 추가 작업이 진행되면서 몇 가지 문제점을 확인할 수 있었다.
- 데이터 모델의 복잡도는 올라감에 따라, 원아워 서버와 람다에 데이터 모델이 중복해서 정의가 되어 있었기에 맞추는 과정에서 어려움이 많았다. (배포 순서, 오타 및 누락)
- AWS SQS 에서 PostgreSQL 에 접근해야 하는 상황이 발생했다. 원아워 API 서버가 불안정한 상태였기에, 트래픽이 몰리는 상황과, PostgreSQL 의 커넥션이 급증하는 상황을 막아야만 했다. 따라서, RDB 에 대한 접근을 허용할 수 없었다.
#4 비즈니스 로직 분리 (2024, 01.14 ~ 01.15)
3번째 프로젝트에서 발생한 문제들을 해결하기 위해 AWS SQS 에서는 원아워 서버의 API 를 호출하는 방식으로 변경했다. 즉, 원아워의 모든 비즈니스 로직은 원아워 API 서버를 통해 관리하며, AWS SQS 는 조금 더 단일 목적 ( ChatGPT 대리 요청 및 전 후처리에 대한 정의 ) 에 집중하게 했다.
개발을 하면서 오토마타 수업때 배웠던 것들이 떠올랐다. 느낌이 비슷했다.
1. 사용자가 AI 기능 요청
2. AI 기능 요청 전에 처리해야할 로직 수행
3. 티켓 발행
4. 티켓 처리 : ChatGPT 에게 요청
5. ChatGPT 응답 수신 후 정의되어 있는 후처리 API 호출
6. 클라이언트에 웹소캣을 통해 결과 전송
# a.py
import requests
def process_response_for_TASK_WRITING_AI(req, res):
payload = ...
url = f"{ONEHOUR_API_SERVER}/~~~"
requests.put(url, res)
return req, res성과
특별한 일이 있지 않는 한, SQS 소스코드를 수정할 필요가 없어졌다. 역할 분리를 통한 유지보수성이 좋아졌다.
마무리
리팩토링한 변화과정을 간단하게 그림으로 보면 다음과 같다.
느낀 점
- 좋은 코드가 결국에는 시간을 단축시켜준다.
- 한번에 완벽하게 만들어낼 수 없다. ( 나중에 경험이 아주아주아주아주 많이 쌓인다고 하더라도, 몇 번의 트러블 슈팅과 리팩토링은 필요할거(같)다??!! )
- AWS 인프라에 대한 다양한 트러블 슈팅 경험을 얻을 수 있었다.
- AI 기능이 시장에서 아주 큰 영향을 미친다는 것을 알 수 있었다.
- 서울시 교육청과의 계약
- 스콜라스틱, 디즈니와 같은 큰 교육 미디어 회사와의 계약
- 시리즈 A 투자 유치에 큰 기여
- 팀원의 역량을 발휘할 수 있게 도와주는 백오피스 시스템의 중요성을 알게 되었다.
아쉬운 점
- AI 의 핵심 기능이라고 생각하는 스트리밍에 대한 처리는 적용해보지 못했다.
- 스타트업 특성상 새로운 기능을 개발하고 유지보수하는 것이 조금 더 강조되었기에 기술적으로 깊게 학습하기에는 어려움이 있었다.
- 다른 기업들에게 서비스를 제공하는 OPEN API 를 만들지 못했다.
'포트폴리오 > 경력' 카테고리의 다른 글
| 원아워 서비스 장악하기 - 중앙 집중식 로깅 시스템 구축 (0) | 2024.09.20 |
|---|