
소개
- 회사 - 제로엑스플로우
- 기간 - 23.07.12 ~ 24.02.21
- 프로젝트 명 - 원아워 중앙집중식 로깅 시스템
- 목적 - 로그 활용
- 참여인력 - 백엔드 · 인프라 개발 1
- 기술스택
- 원아워 서비스 - Python, Django, AWS Lambda
- 로그 시스템 - Python, AWS SQS, AWS Lambda, AWS Cloudwatch, Terraform, AWS Log Insight
- 로그 스트리밍 - AWS APIGateway(Websocket), DynamoDB, html
- 담당 - 백엔드 · 인프라 개발
도입
로그는 사용자들이 서비스를 이용한 내역이자, 프로그램의 동작에 대한 기록이며 일반적으로 시스템에서 발생하는 오류를 진단하고, 빠르게 해결하기 위해 참고하는 과거의 기록이다. 하지만 단순히 문제 해결만을 위해 사용한다고 생각하지는 않는다. 로그는 개별로 있을 때 큰 의미가 없을 수 있지만, 여러 개의 로그가 모인다면 더 다양한 용도로 활용할 수 있다고 생각한다. 그 예시로 작게는 특정 사용자에 대한 분석, 새로운 기능의 활성화 정도 및 사용성 검증, 크게는 기업의 방향성 설정 등 다양한 분야에 필요한 근거를 만들어 준다고 생각한다.
원아워 서비스는 Sentry 라는 서비스를 사용하고 있었지만, 이러한 데이터를 단순히 버그가 발생했는지 체크하는 용도로만 쓰고 있었으며, 팀 내에서 Sentry 를 통한 오류분석과 대응에 어려움이 있었다.
AWS Lambda 를 사용하고 있었기에, AWS 인프라의 기능을 활용해서 로그를 보다 적극적으로 해결해 보고자 프로젝트를 시작하게 되었다. 프로젝트를 진행하면서 달성하고자 하는 목표는 다음과 같이 설정했다.
- 성능 영향 최소화: 로그 수집 방식이 서비스 성능에 영향을 주지 않아야 한다.
- 통계 데이터 추출: 다양한 통계 자료 추출이 가능해야 한다.
- 로그 러닝커브 감소: 팀원의 로그 활용이 쉬워야 한다.
- 개발시간 최소화: 로그 시스템 구축에 필요한 시간을 줄여야 한다.
- 여러 서비스 통합: 다양한 서비스 로그 수집이 가능해야 한다.
프로젝트에 대한 글을 작성하는 현시점에서 고려하지 못했던 점, 학습이 부족했던 부분들이 몇몇 발견되었다. 해당 내용에 대해서는 마지막에 같이 다뤄보려고 한다.
요약
목표 별
- 성능 영향 최소화
- 로그 생성을 메세지큐를 활용하여 네트워크를 통한 로깅 방식을 채택.
- AWS SQS 를 활용하여 로그 수집 및 전처리 작업 수행
- 통계 데이터 추출
- AWS Cloudwatch 를 이용하여 로그 저장, 로그 집계 및 분석
- 로그 flatten 작업을 통한 필터 작업 난이도 낮춤
- 로그 러닝커브 감소
- AWS Cloudwatch 내 Logs Insights 에 다양한 쿼리 샘플 저장
- 개발시간 최소화
- Elastic 계열의 로그 시스템에 대해서 잘 알지 못했기에 AWS SQS 와 AWS Cloudwatch 를 활용하여 구축
- 여러 서비스 통합
- 백엔드 이외의 서비스(웹, 앱, 배치 서버)의 로그를 수집할 수 있도록 AWS SQS 에 메시지를 보낼 수 있는 람다 함수 등록
일정
| 내용 | 기간 | |
| 1차 | SQS 를 활용한 네트워크 로깅 시스템 구축 | 23.07.02 ~ 23.07.04 ( 유지보수 : ~ 23.07.28 ) |
| 2차 | 로그 전처리 작업을 통한 로그 활용 러닝커브 낮추기 및 다양한 통계 데이터 추출 | 23.09.08 |
| 3차 | 클라이언트와 배치서버의 로그 수집 | 23.09.13 ~ 23.09.14 ( 유지보수 : ~ 23.10.06 ) |
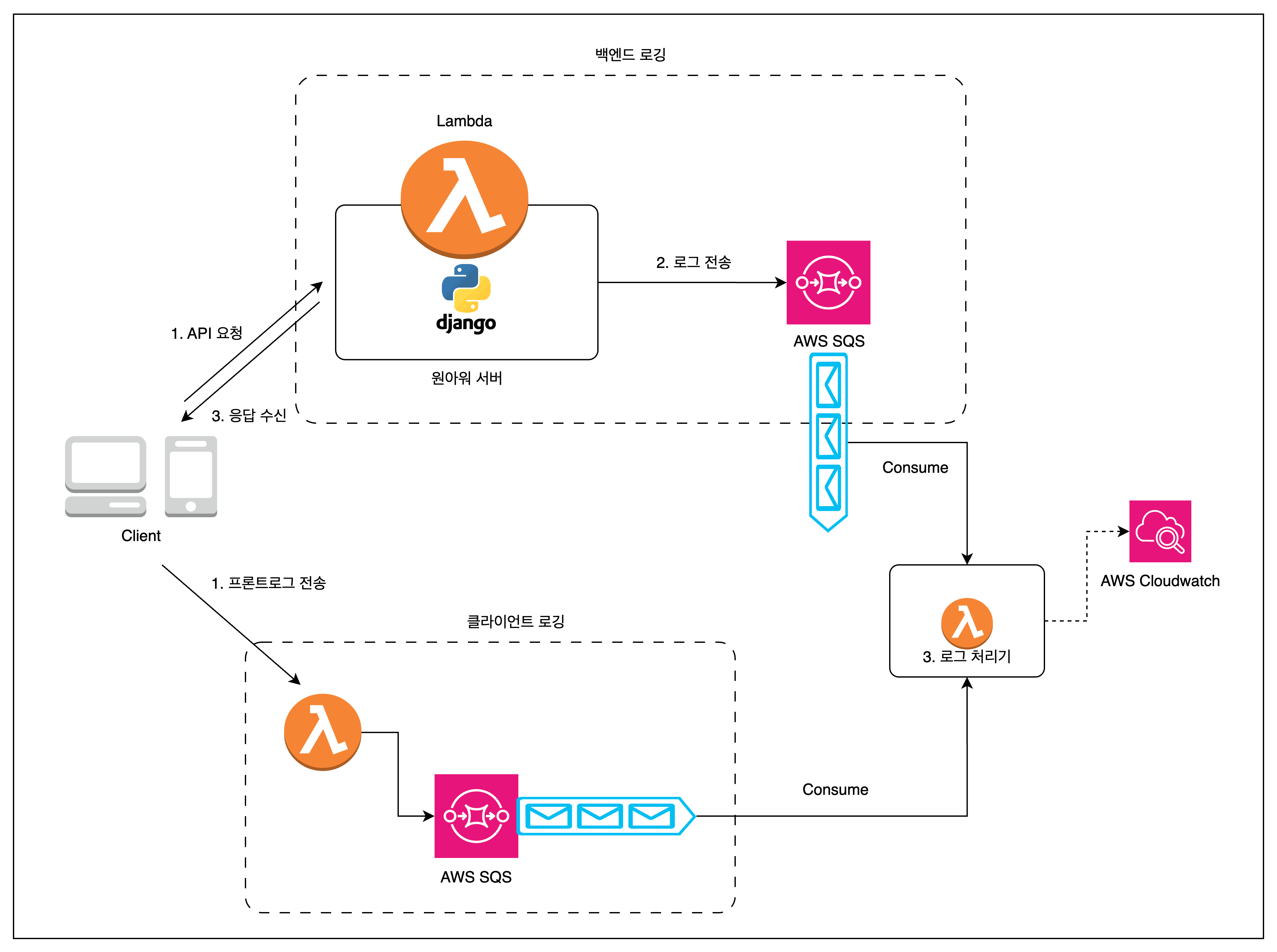
#1 SQS 를 활용한 네트워크 로깅 시스템 구축
원아워의 백엔드에서 별다른 로그를 남기고 있지 않았다. `Sentry` 서비스를 이용하여 로그를 수집하고 있었다. 이를 통해 어떤 API 가 얼마나 호출되었는지, 실행시간을 평균적으로 어느 정도 소요되는지, 어떤 API 에서 오류가 발생했는지 와 같은 정보들을 수집할 수 있었다.
하지만, 실제로 사용자가 겪는 버그와 문제는 CS 담당직원과의 전화를 통해 파악 및 해결하고 있었고, 개발자가 버그가 생겼다는 것을 CS 직원들 통해 듣고 있었다. 그렇기에 오류가 발생했을 때, 사내에서 사용하는 Slack 이라는 메신저에 알림이 오도록 API 를 호출하려고 했으나, 해당 작업을 원아워 서비스 내에서 처리하기에는 서버의 트래픽이 부담이 되었다. 따라서, 메세지 큐인 AWS SQS 를 활용하여, 백엔드에서 발생한 로그 데이터들을 AWS SQS 메시지로 전송하여, 해당 메시지를 Cloudwatch 에 대신 남기고, 오류에 관련된 로그가 있다면, Slack 알림을 보낼 수 있게 했다. AWS Cloudwatch 는 네트워크 로깅을 이용하고 있었기에 로그가 즉시 저장되지 않았다. 배치 서버를 활용하는, 실제 인프라를 기반으로 특정 기능에 대해서 테스트를 할 때 로그가 바로 확인되지 않는다는 것이 생각보다 시간을 많이 잡아먹고 있었다. 이러한 문제 또한 간단한 웹소캣을 활용한 웹사이트를 만들어, AWS SQS 에서 특정 로그들을 웹소캣을 통해 수신받을 수 있도록 처리했다. 화면을 그리는 것보다, chrome 브라우저의 console 을 활용헀으며, 이를 통해 검색, 필터링과 같은 처리를 직접 구현하지 않아도 되었기에 개발 시간을 절약할 수 있었다.
성과
- 네트워크 로깅을 통해 Slack API 를 사용할 수 있게 되었다. 이를 통해 사용자들의 문제를 보다 빠르게 접할 수 있게 되었다.
- 개발 및 테스트 단계에 있어서 병목을 줄였다.
트러블 슈팅
- 처음 서비스를 런칭했을 때, SQS 설정을 따로 않았기에 큐에서 메시지를 한개씩 소모했고, 로그는 찍히고 있었기에 문제가 없는 줄 알았으나, 점차 시간이 흐르자, 출력되고 있는 로그의 시간과 현재시간이 크게 다르다는 것을 확인함
- `WaitTimeSeconds` 와 `MaxNumberOfMessages` 설정을 통해 해결
문제점
간단한 오류를 파악하는 것은 보다 수월해졌으나, 문제 원인이 클라이언트에 있는지, 서버에 있는지 와 같은 보다 여러 로그를 같이 분석해야 파악할 수 있는 문제들은 여전히 처리가 어려웠다.
#2 로그 전처리 작업을 통한 로그 활용 러닝커브 낮추기 및 다양한 통계 데이터 추출
많은 로그들을 수집할 수 있게 되었으나, 해당 로그를 활용해서 의미 있는 데이터 지표를 뽑아내는 것에 어려움이 있었다. 로그 데이터를 Logs Insights 에서 원하는 데이터를 뽑기 위해 조건을 설정하는 부분에 있어, json depth 와 정규화 여부가 걸림돌이었다. 이를 해결하기 위해 정규화가 가능하도록 데이터 마사지를 거친 후, json depth 를 1 뎁스로 낮추기 위해 flatten 작업을 수행했다.
해당 작업을 통해, Logs Insights 에서는 다음과 같은 다양한 조건 처리가 간편해졌다.

이러한 쿼리들 중 과제별 대시보드 사용성 개선을 한 이후에 고객들의 반응을 들어보았고 일부 고객의 목소리를 통해 기능이 어느정도 좋은 영향을 미치고 있음을 짐작할 수 있으나, 그 영향력의 크기를 파악하는 것은 어려웠다. 그 이유는 불편한 것을 얘기할 뿐, 긍정적인 부분에 대해서 피드백을 남기는 고객은 극소수이기 때문이다.
따라서 이런 상황에서는 정량적인 통계 정보가 필요하며, 이를 Logs Insights 를 통해 얻어낼 수 있었다.


약 5주간 20000번의 사용량이 1주일만에 43200번으로 급증하게 되었다. 기간별 사용량만을 보았을 때, 많은 유저들이 사용하고 있음을 알 수 있었다.
성과
사용자의 피드백이 없더라도 다양한 목적으로 정량적인 통계 정보를 쉽게 얻어낼 수 있게 되었다.
러닝커브를 낮춤으로써 Logs Insights 를 사용하는 동료 팀원들의 시간을 절약할 수 있었다.
#3 클라이언트와 배치서버의 로그 수집
사용자들이 겪는 오류에는 백엔드로그만으로 파악하기 어려운 상황도 존재했다. 실제로 클라이언트에서 상태가 잘못 관리가 되어있는 경우도 있었으며, 이미 상태가 복잡하게 얽혀있었고, 해당 상황을 재현하는 것도 정말 어려운 상황이었다. 그렇기에 클라이언트에서 발생하는 문제들 또한 로그로 남기기 위해 SQS 에 메시지를 전송해주는 간단한 람다 함수를 정의했다.
성과
- 클라이언트에서 발생하는 다양한 오류들을 조금 더 빨리 해소할 수 있게 되었다.
- (GA 와 유사한?) 클라이언트에서 사용자의 행동(페이지 이동, 특정 버튼 클릭) 과 같은 다양한 로그들도 수집할 수 있게 되었다.
문제점
상태가 잘못 관리되어 있는 상황에서 리랜더링이 반복적으로 일어나며, 특정 로그들이 기하급수적으로 늘어나는 상황이 발생했다.
마무리
느낀점
로그를 잘 수집한다는 것이 기업의 성장에 있어, 방향성 설정과 회고에 있어 얼마나 중요한 것인지 몸소 깨달을 수 있었으며, 더 좋은 기술스택을 이용하여 보다 개선된 로깅 시스템을 구축해보고 싶다는 생각이 들었다.
아쉬운 점
- #3 의 문제점에 대해서 클라이언트의 로그를 줄이는 방법과 상황이 발생했을 때, 빠르게 대응하는 정도로 타협했고, 근본적으로 문제를 해결하지는 못했다.
- Logs Insights 를 이용하여 검색하는 경우, 비용이 꽤 많이 들었다. 이를 해결하기 위해 S3 로 데이터 이전, Athena 활용을 시도해보았으나, 새로운 기능을 개발하는 것이 더 중요하다고 회사에서 판단하여 해보지 못했던 점이 아쉽다.
- 러닝커브와 개발시간 최소화라는 목표로 인해 kafka 나 elasticsearch, grafana, prometheus 와 같은 다른 기술들을 비교해보지 못했다.
'포트폴리오 > 경력' 카테고리의 다른 글
| AI 코스웨어에 한 걸음 다가가기 - ChatGPT 배치 서비스 구축 (0) | 2024.09.08 |
|---|